Data Vault Modellierung- Teile und Beherrsche
Die Data Vault Modellierung ist fachbereichsorientiert. Sie zerlegt die Quellsysteme in ihre Bestandteile und ordnet sie nach gemeinsamen Geschäftsobjekten und deren Geschäftsbeziehungen an.

| Hub | Link | Satellit |
|---|---|---|
| Der Hub enthält die Liste der eindeutigen, fachlichen Geschäftsschlüssel. | Der Link verbindet Hubs. | Der Satellit enthält beschreibende Attribute für Geschäftsobjekte oder Geschäftsbeziehunngen |
| Er ist die Basis für die Integration von Quellsystemen. | Er entkoppelt das Modell und ist die Basis für deren Skalierbarkeit. | Er historisert Geschäftsattribute. |
Das Netzwerk aus Hubs und Links bildet das Rückgrat des Data Vault Modells. Zuerst werden die Geschäftsobjekte und Geschäftsbeziehungen definiert. Danach werden die restlichen beschreibenden Attribute des Quellsystems historisiert und als Satelliten an die zugehörigen Hubs oder Links angehängt. Dadurch werden die unterschiedlichen Quellsysteme automatisch nach gemeinsamen Geschäftsobjekten und Geschäftsbeziehungen strukturiert und vorintegriert:
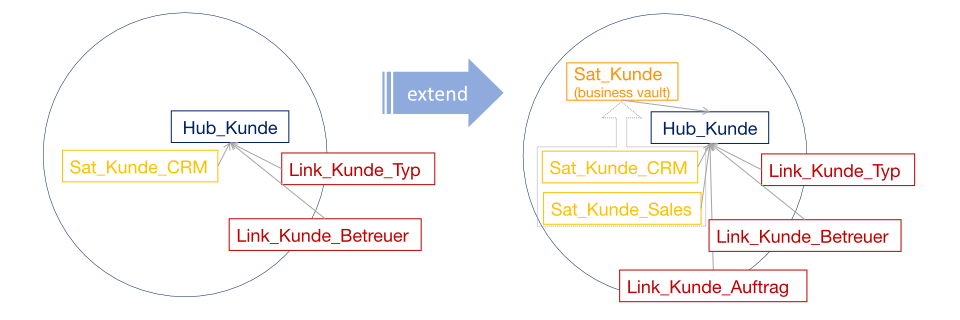
Bei mehreren Quellsystemen reduziert Data Vault die Komplexität zusätzlich. Neue Datenquellen führen zu rein additiven Änderungen. Es werden einfach Hubs, Links und Satelliten zum bestehenden Modell angehängt.
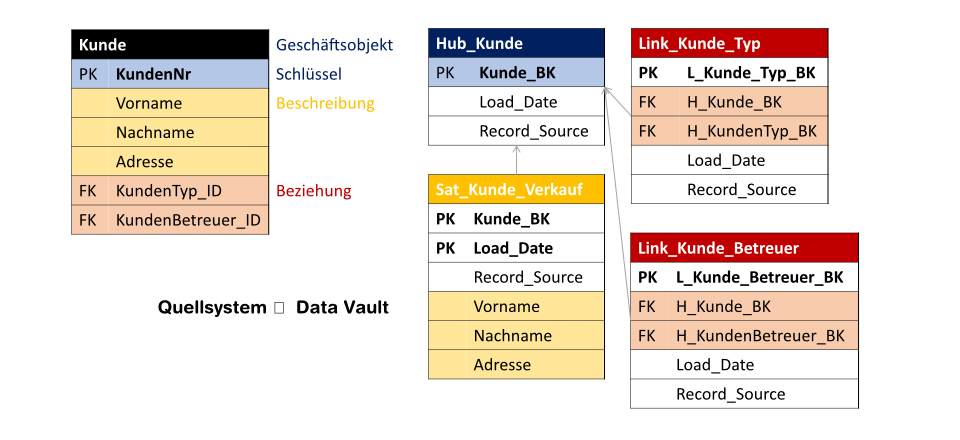
Hub_Kunde und seine Satelliten bilden eine logische Einheit und beschreiben das Geschäftsobjekt Kunde. Die Geschäftsregeln zur Datenintegration werden strikt getrennt im Business Vault implementiert. Die Links sind die Beziehungen und entkoppeln Kunde von den restlichen Geschäftsobjekten. Das macht das Datenmodell sehr flexibel. Abhängigkeitsketten im Ladeprozess werden aufgelöst und alle Quellen können gleichzeitig geladen werden.
Data Vault Schichten
Die Datenlandschaft eines Unternehmens mit mehreren Quellen ist komplex und umfangreich. Über mehrere Schichten wird aus den verfügbaren Daten wertvolle Information und Wissen erzeugt.
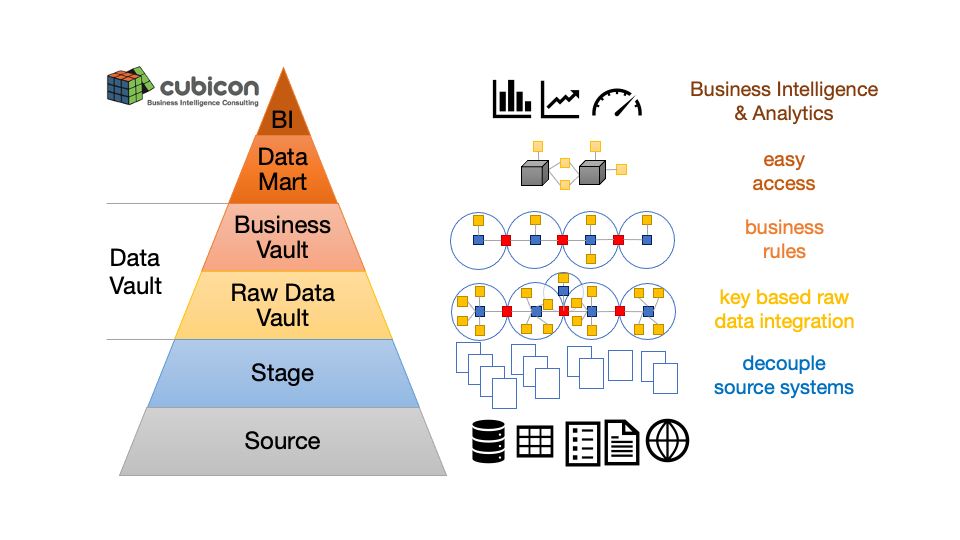
Auch die Architektur teilt das Datawarehouse (DWH) in mehrere Schichten mit klaren Zuständigkeiten:
- Die Stage enthält einen Abzug der Quelldaten. Sie entkoppelt die Quellsysteme vom Datawarehouse.
Die Integration erfolgt über zwei Schichten, die im Data Vault Stil nach Dan Linstedt modelliert werden:
- Der Raw Data Vault integriert die Rohdaten der Quellsysteme über gemeinsame Geschäftsschlüssel in den Hubs und verknüpft diese mit Links. Der beschreibende Geschäftskontext wird über quellsystemspezifische Satelliten historisiert. Alle verfügbaren Attribute der Quellsysteme werden so einem Geschäftsobjekt zugeordnet. Dadurch eignet sich Data Vault auch sehr gut für analytisches Master Data Management. Nur harte Geschäftsregeln wie Deduplizierung, Datentypkonversionen, Normalisierung und Denormalisierung sind im Raw Data Vault erlaubt.
- Der Business Vault konsolidiert die Quellsystemattribute in ein Fachbereichsmodell und implementiert die Geschäftsregeln des Fachbereichs. Geschäftsregeln ändern sich schnell. Durch die strikte Trennung der Rohdaten im Raw Data Vault von den Geschäftsregeln im Business Vault können diese Änderungen schnell umgesetzt werden. Nur hier sind inhaltliche Veränderungen, auch weiche Geschäftsregeln genannt, erlaubt.
- Die Data Mart stellt das Fachbereichsmodell im Business Vault als leicht abfragbares Star Schema bzw. als Cube zur Verfügung. Die Datenmodellierung erfolgt hier meist dimensional im Stil von Ralph Kimball.
- Business Intelligence (BI) & Analytics bezeichnet die Analysetools und Dashboards, die zur Auswertung und Anzeige der Informationen eingesetzt werden.
Data Vault ist technologieunabhängig. Die Methode funktioniert mit relationalen und Big Data Technologien. Eine persistierte Stage bzw. ein Data Lake ist oft die Basis für die oberen DWH Layer. Bei Streaming Anwendungen wird direkt in den Raw Vault geschrieben.
Data Vault unterstützt die einfache Einbindung von Erkenntnissen aus Data Science Analysen: Ein Featureset für Machine Learning und Künstliche Intelligenz Algorithmen kann sowohl aus Rohdaten als auch aus Businessdaten erzeugt werden. Die Ergebnisse werden einfach als Satellit wieder zurückgeschrieben.
Durch die klare Trennung von Zuständkeiten sowohl im Datenmodell als auch bei den Architekturschichten ergibt sich ein hoch standardisiertes Datawarehouse, das alle Voraussetzungen für eine umfassende Automatisierung erfüllt.
 Thomas Herzog
Thomas Herzog