Data Vault im Vergleich zu klassischen DWH Methoden
Data Vault ist eine Weiterentwicklung der klassischen Data Warehouse Methoden von Ralph Kimball und Bill Inmon.
| dimensionales DWH | DWH in 3. Normalform | Data Vault 2.0 DWH |
|---|---|---|
| Ralph Kimball | Bill Inmon | Dan Linstedt |
| Star Schema, Cube | 3.Normalform | flexible, pattern-basierte Hub & Spoke Architektur |
| optimiert für Datenanalysen | optimiert für Datenintegration |
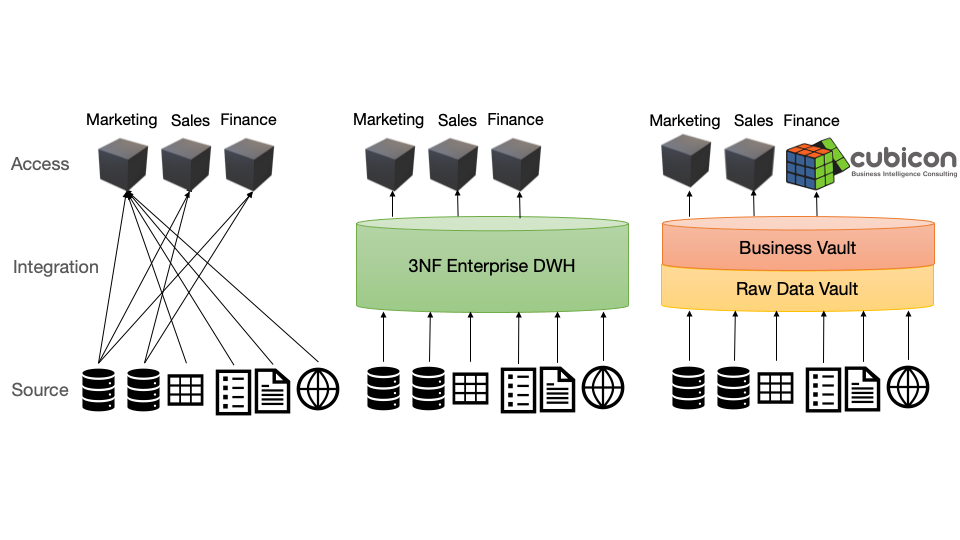
Die dimensionale Modellierung von Kimball hat den Fokus auf einfache Datenanalysen und ist optimal für die Zugriffsschicht eines Data Warehouses.
Die Inmon Schule propagierte eine Enterprise- Integrationsschicht in 3. Normalform, die alle Quellsysteme in ein einheitliches, historisiertes Fachbereichsmodell transformiert. Die Modellierung in 3. Normalform ist optimiert für operative Systeme und stößt bei Datenintegration schnell an seine Grenzen.
Seit 2010 empfiehlt auch Bill Inmon die Data Vault Modellierung für die Integrationsschicht.
Die größten Nachteile der klassischen Data Warehouse Methoden sind:
- Frühe Transformation in das Fachbereichsmodell.
- Enge Kopplung des Datenmodells.
- Komplexe Ladeprozesse, die zu viele Aufgaben übernehmen.
Änderungen haben dadurch große Auswirkungen und sind entsprechend teuer. Das behindert das Wachstum des Data Warehouses, da notwendige Änderungen aus Kostengründen vermieden werden.
Die Data Vault 2.o Methode von Dan Linstedt hat den Fokus auf Flexibilität und einfache, schrittweise Integration von Daten. Sie ist optimal für die Integrationsschicht eines Data Warehouses. Durch kleinere Transformationsschritte wird die Architektur standardisiert, die Wiederverwendung der Daten gefördert und die Agilität erhöht. Änderungen werden dadurch billiger.
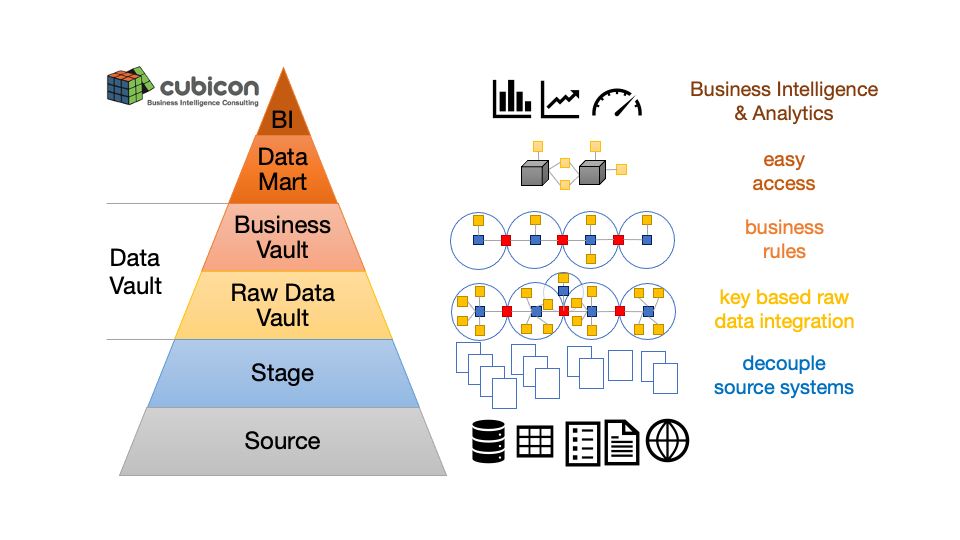
Die Datenpyramide symbolisert dass nur ein Teil der vorhandenen Daten für Entscheidungen relevant ist und über mehrere Schichten in hochwertige Informationen transformiert wird.
Die Stage dient der Entkopplung der Quellsysteme vom Datawarehouse.
Die Integrationsschicht im Data Vault unterscheidet strikt zwischen Rohdaten und angereicherten, inhaltlich veränderten Daten.
Der Raw Data Vault ordnet die Rohdaten nach Geschäftskonzepten an. Der Fokus ist auf Identifizierung der Geschäftsschlüssel und Geschäftsbeziehungen sowie auf Historisierung. Es werden nur harte Geschäftsregeln angewendet. Das sind Deduplizierung, Datentypkonversionen sowie Normalisierung/ Denormalisierung der Daten.
Im Business Vault werden die weichen Geschäftsregeln angewendet. Daten werden anhand der Spezifikation des Fachbereichs harmonisiert, angereichert bzw. berechnet. Nur hier sind inhaltliche Transformationen erlaubt.
Der Business Vault kann jederzeit gelöscht werden und aus dem Raw Vault neu berechnet werden. D.h. im Gegensatz zu klassischen Data Warehouse Architekturen, wo Geschäftsregeln sofort angewendet werden, werden Änderungen der Spezifikation im Data Vault schnell und effizient umgesetzt.
Die Data Vault 2.0 Methode erhöht die Flexibilität der Integrationsschicht durch konsequente Zerlegung in klar strukturierte Komponenten mit eindeutigen Zuständigkeiten. Das führt zu einfachen, überschaubaren Ladeprozessen, die gut automatisierbar sind.
Diese Zerlegung wird in der Data Vault Modellierung konsequent fortgesetzt.
 Thomas Herzog
Thomas Herzog